

近日,TRANS课题组参与研究于进化计算领域中科院一区TOP期刊《IEEE Transactions on Evolutionary Computation》(影响因子12)发表《Evolutionary Reinforcement Learning with Late-start Evolution and Clustering Archive》。本研究在进化强化学习方向实现三项关键创新:
- 训练更稳定:晚启动策略规避早期不良经验影响;
- 搜索更高效:双向对称近端变异生成高质量个体;
- 泛化更强:聚类归档选择方法维持策略体的多样性。
此项研究突破了进化强化学习在稳定性、效率与泛化三大瓶颈,推动强化学习算法向可工程化、可部署、可规模化应用加速迈进。
论文第一作者华南理工大学未来技术学院 2023级硕士生蔡秋婷,通讯作者为贾亚晖副教授,合作作者包括TRANS课题组欧士琪教授,华南理工大学计算机科学与工程学院陈伟能教授等。
✨ 论文摘要
演化强化学习(ERL)将进化算法与强化学习相结合,为智能决策带来了新的范式,但传统方法常因个体质量与策略多样性难以兼顾而产生经验错配,影响训练效率与稳定性。
针对这一问题,本研究提出了全新的LCERL框架,通过晚启动策略避免早期低质量经验对强化学习的干扰,确保训练过程更加稳健;通过双向对称近端变异生成更高质量的策略个体并自适应调整变异幅度,实现更高效的高维搜索;同时结合基于表型的聚类归档选择机制,引入多样化行为经验以提升泛化能力。
大量实验结果表明,LCERL在MuJoCo基准任务及真实能源调度场景中均展现出优于现有进化强化学习与强化学习方法的性能,具有更快的收敛速度、更强的稳定性与更高的工程可用性。
✨ 研究流程框架
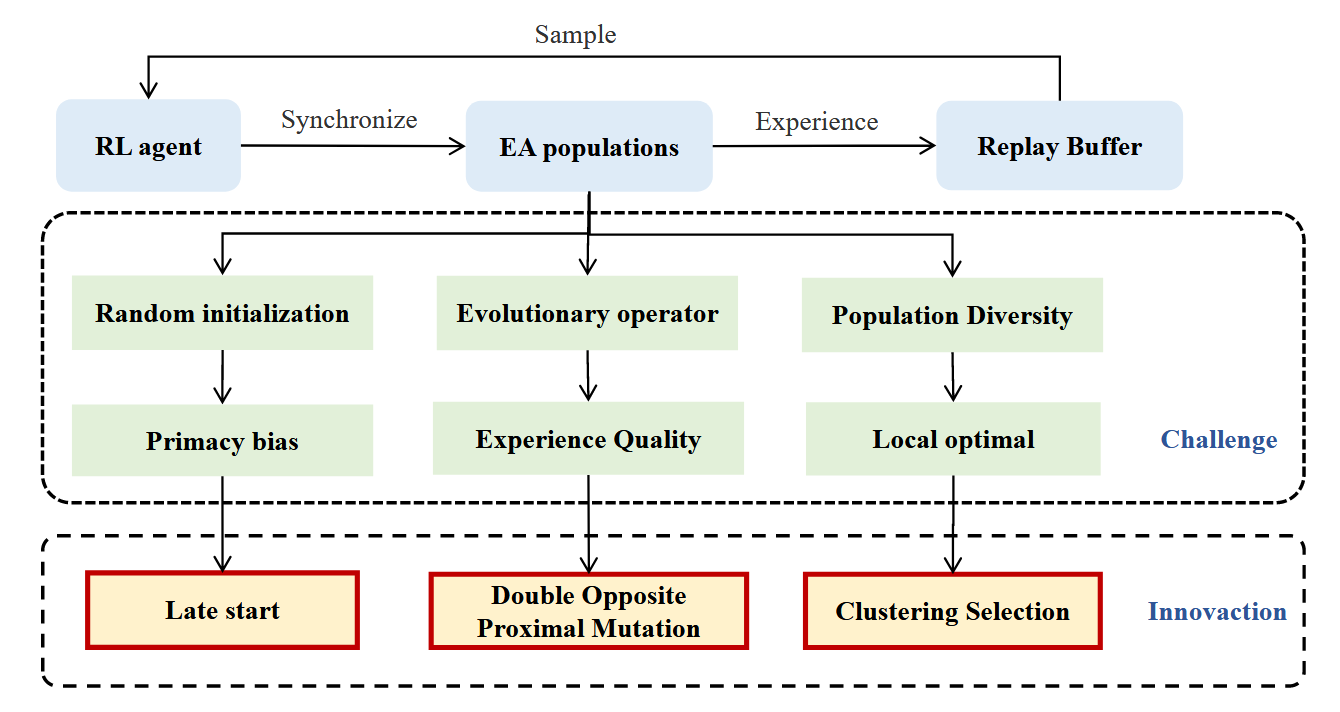
图 LCERL的动机和设计原理。
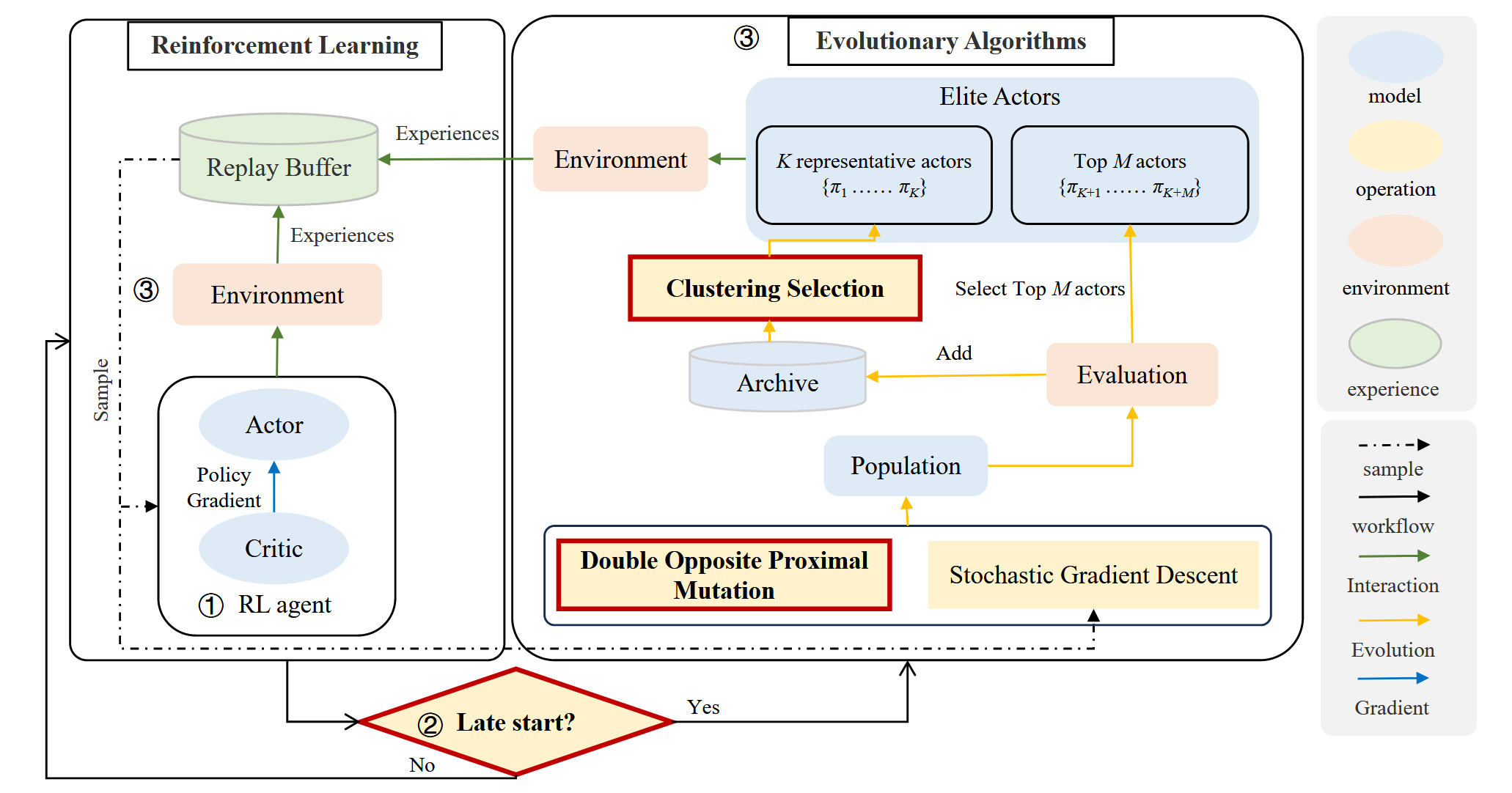
图 LCERL框架。左为强化学习部分,右为进化算法部分,其中三个红框为本研究提出的创新点。
✨ 主要方法
(1)模型框架
为了让强化学习(RL)能够获得更高质量、更具多样性的训练经验,本研究提出了一个全新的协同框架 LCERL。它的核心目标非常明确——通过进化算法(EA)持续生成优质经验,帮助RL更快、更稳地学出好策略。在LCERL中,EA不再独立维护一个额外的“种群”,所有新个体都是从当前RL策略变异而来,从而避免传统ERL中“经验水平与RL学习阶段不匹配”的问题。
整个框架围绕这一思想嵌入了三项关键机制:晚启动策略用于确保早期经验质量不拖累RL;双向对称近端变异让生成的策略更高效、更贴合当前RL的学习阶段;基于行为表型的聚类归档选择则保证经验来源始终保持多样性。这三项机制共同作用持续为RL提供高质量且多样的训练经验。
在训练过程中,RL智能体首先与环境交互,采样经验更新网络;当训练步数达到设定阈值后,EA才开始介入,基于当前策略生成多个新个体,并将其加入归档池。归档池会保持固定容量,通过淘汰低质量个体来提升整体质量。接下来,算法会从归档中和新生成的个体中分别筛选出精英策略(其中归档部分使用聚类方法保证多样性,新生成部分挑选性能最优个体),这些精英策略会进一步与环境交互生成经验,再统一加入replay buffer中,持续推动RL的训练。最终,在所有策略中表现最好的那个,将被作为最终输出模型。
借助这种“RL主导 × EA辅助 × 三重机制增强”的协同设计,LCERL能够有效提升RL在复杂任务中的学习效率、探索能力和模型稳定性。

图 算法伪代码。
(2)晚启动策略
在训练初期,进化算法(EA)的强探索会带来大量随机性,产生许多低质量个体和低回报经验,而深度强化学习(DRL)在此阶段对这些低质量经验进行近似不仅成本高、收益低,还会干扰后续策略优化。虽然 LCERL中的EA个体来源于强化学习(RL)个体的变异,但由于RL早期性能较弱,这些变异生成的个体质量也难以提供有效帮助。
为缓解上述问题,本研究提出了晚启动策略。该策略的核心思想是延迟引入高强度的探索,使RL智能体能够在较稳定的学习轨迹上完成基础策略的建立,然后再逐步增加探索力度。通过这种方式,RL能够在训练初期有效利用梯度信息学习基本策略结构,避免EA随机性带来的不利干扰。由于晚启动策略对RL智能体的训练至关重要,在LCERL中,采用了RL训练步数作为启动EA组件的衡量依据。假设RL总训练步数为Tep则 EA的启动时刻TEA定义为:
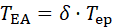
其中,δ为可调节的超参数。
借助晚启动策略,RL的初期学习变得更加稳健,EA的探索也能在更合适的时机介入,实现协同增益,为整个算法的收敛效率和稳定性打下了坚实基础。
(3)双向对称近端变异
为了进一步提升策略搜索的效果,本研究在算法中设计了“双向对称近端变异”机制。相比传统只依赖单方向扰动的做法,该机制会同时对策略参数施加正向与反向两个扰动,并分别计算扰动前后的性能差异,再从中选择表现更优的一支作为最终的变异结果。与此同时,本研究还引入了自适应调节因子,用于根据变异前后性能的变化自动放大或缩小扰动幅度:当变异提升了策略质量,就扩大步长以进一步探索;当变异变差,则缩小步长以保持收敛稳定性。为了避免陷入局部最优,加入了重变异机制——若一次变异没有带来改进,就自动增大扰动范围并重新执行变异,使搜索能够覆盖更广空间、获得更高质量的候选策略。
通过这套双向扰动、自适应调节与重变异结合的设计,算法能够在复杂高维空间中保持更强的探索能力,并在当前解附近进行更细致的局部搜索,从而提高整体优化效率与稳定性。
(4)聚类归档选择
在演化算法中,每个个体不仅有基因结构,还表现为具体的“行为方式”。在LCERL中,本研究直接以强化学习策略体在不同状态下的“动作表现”来描述其行为特征,因为与环境互动产生的动作,才是真正决定策略优劣的关键。为了从归档池中挑选出具有代表性的“精英策略体”,本研究设计了一套基于行为表型的聚类选择机制。
具体来说,本研究先从共享的replay buffer中随机采样若干状态,让归档中的每个策略体依次在这些状态下输出动作序列。这个动作序列就被视为策略体的“行为特征”。随后,对所有行为特征执行K-means聚类,把表现相似的策略体分到同一组。每一簇可以看作是一种“行为模式”。在完成聚类后,再从每一簇中挑选出表现最好的代表性策略体,构成最终的精英集合,用于生成具有差异性的训练经验。
借助这种基于表型的聚类选择机制,算法能够从多种行为模式中均衡抽取高质量策略,避免经验过度集中于单一风格,实现经验多样性与策略泛化能力的双提升。
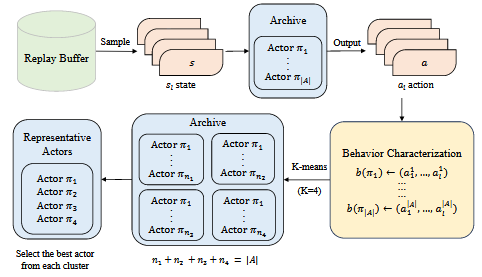
图 聚类选择的过程(假设有K=4个簇)。
✨ 主要结果
为了系统评估LCERL的性能,本研究在六个经典MuJoCo连续控制任务(HalfCheetah-v4、Hopper-v4、Humanoid-v4、Swimmer-v4、Walker2d-v4、Ant-v4)上进行对比实验,并选择多种代表性的ERL与RL算法作为基线方法,包括ERL、CERL、CEM-RL、PDERL、ERL-TD、SAC、PPO、TD3、DDPG等。所有算法均使用社区推荐的公开超参数,保证公平比较。
此外,我们还进行了三类消融实验,分别验证晚启动策略、双向对称近端变异、聚类归档选择三个关键机制的独立贡献。最后,我们将LCERL部署到真实的多能源管理(MEMG)调度任务中,检验其实用性与泛化能力。
(1)综合对比结果
下图展示了各算法在六个MuJoCo任务中的表现;下表给出了最终平均回报、标准差以及显著性检验结果。整体来看,LCERL在六个任务中表现最为突出。在除Walker2d-v4与Ant-v4外的所有环境中,LCERL均取得最高平均回报;在这两个环境中,其表现也分别排名第二与第三。
Wilcoxon显著性检验表明,LCERL在大多数环境中显著优于其它算法;Friedman排名分析显示LCERL的整体平均排名最高(2.2),验证了其跨任务的一致性与稳定性。尤其在梯度方法易受欺骗性梯度影响的Swimmer-v4中,LCERL明显优于其它RL与ERL方法。总体而言,结果证明LCERL在性能、稳定性和泛化性上均显著优于现有算法。
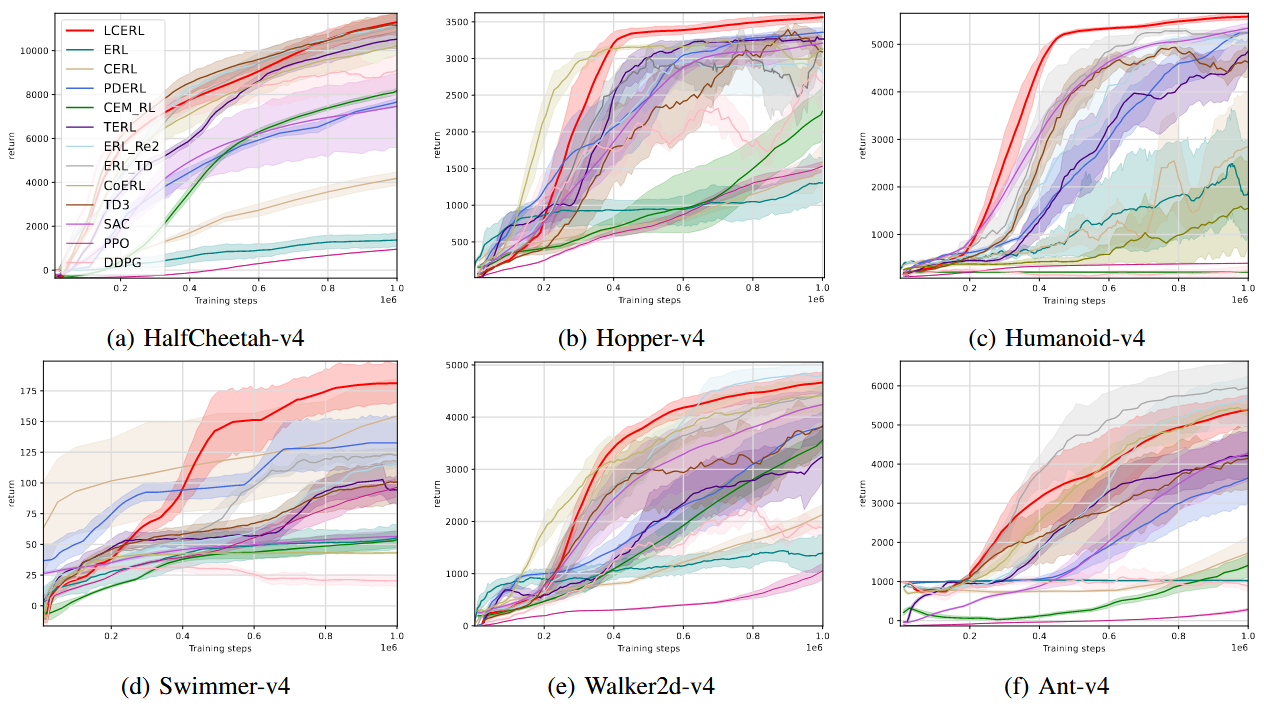
图 各算法的在HalfCheetah-v4(a)、Hopper-v4(b)、Humanoid-v4(c)、Swimmer-v4(d)、Walker2d-v4(e)以及Ant-v4(f)环境上的平均返回值和标准偏差。
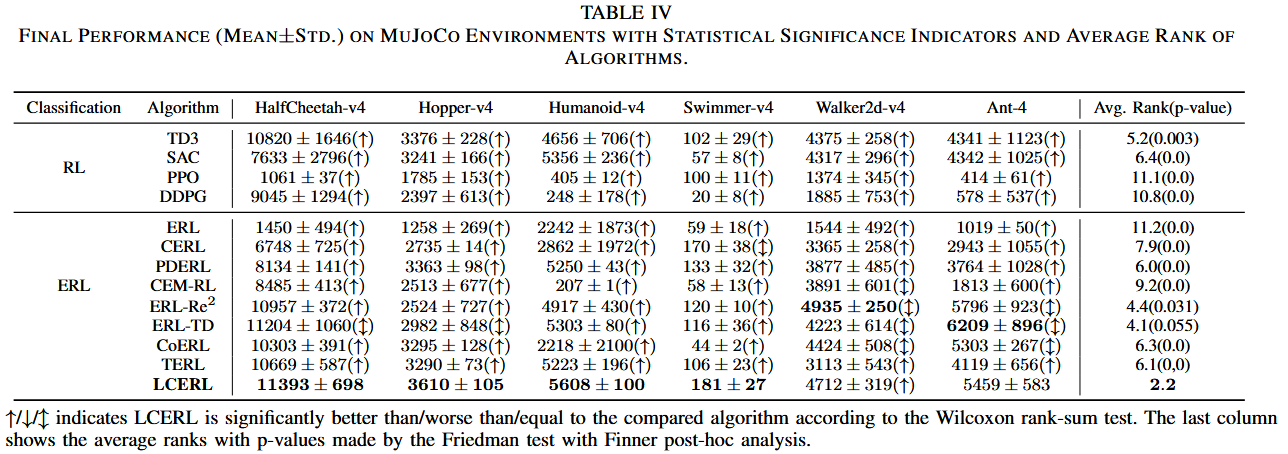
表 各算法在MuJoCo环境上的最终性能(均值 ± 标准差),并附带统计显著性指标与各算法的平均排名。
(2)消融实验
为验证三大机制的独立贡献,我们分别移除“晚启动策略”“双向对称近端变异”“聚类选择机制”进行消融实验。结果表明,这三项机制均对LCERL的性能至关重要,缺一不可。
- 晚启动策略(Late-start Strategy)
在移除晚启动策略的情形下,EA从训练开始便强力介入,早期产生的大量低质量经验会污染经验池,使RL 价值估计出现偏差,导致学习效率下降。对比下图可见:LCERL若不使用晚启动,前期略快,但很快被高噪声经验拖累;使用晚启动后,模型前期略慢,但在200k步后迅速反超,收敛更稳定。
实验表明,晚启动有效避免了“早期随机经验的负面效应”,显著提升后期稳定性与整体性能。
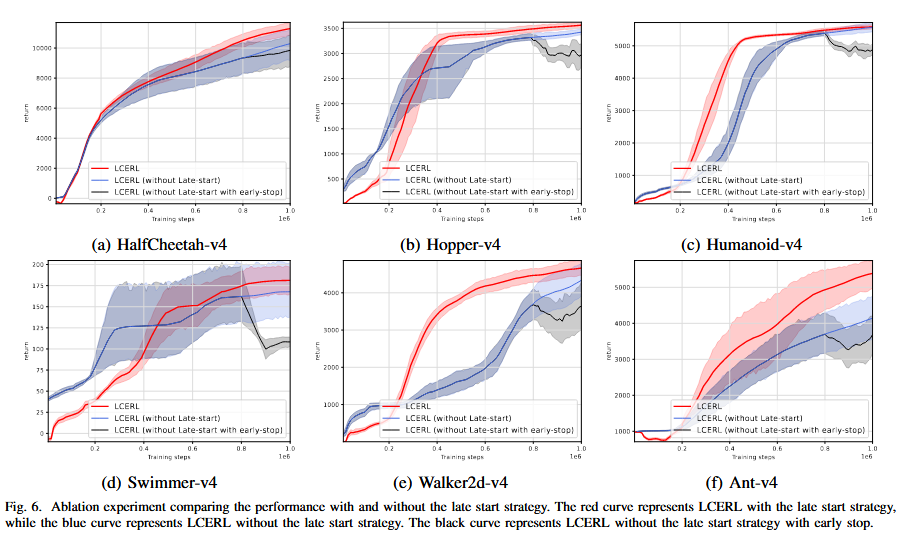
图 有无晚启动策略的性能对比消融实验。
- 双向对称近端变异(Double Opposite Proximal Mutation)
将该机制替换为传统近端变异后,算法在多个任务中(Hopper、Humanoid、Swimmer、Walker2d)均出现性能下降如下图所示。双向变异通过引入两组对称扰动与动态步长,使EA在高维策略空间中探索更稳定,并能持续产生更高质量样本。该机制显著改善了EA贡献样本的质量,从而提升RL训练效率。
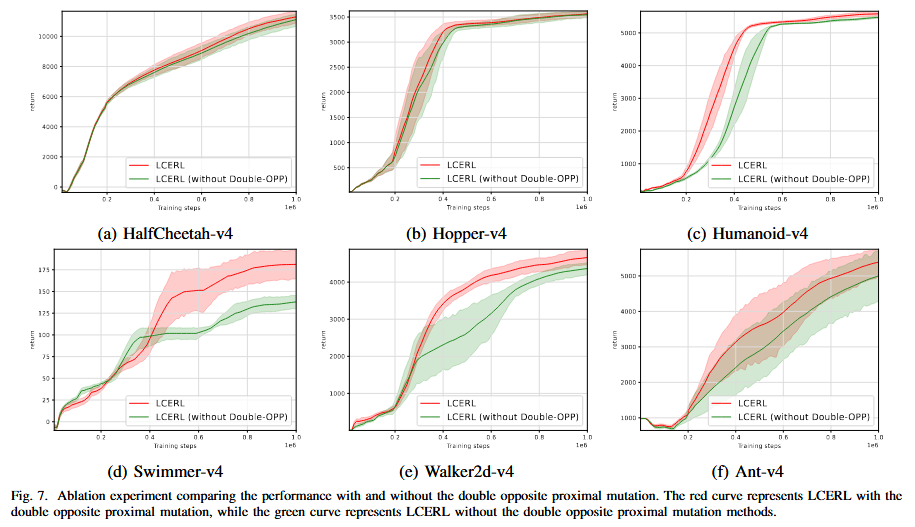
图 有无双向对称近端变异策略的性能对比消融实验。
- 聚类选择机制(Clustering Selection with Archive)
移除聚类选择后,EA产生的经验多样性下降,导致策略容易陷入单一模式(Fig. 8)。聚类选择可在档案池中选取K个行为差异大的精英个体,为RL提供丰富且稳定的样本来源。除部分环境(如HalfCheetah)影响较弱外,多数场景都证明该机制能显著推动性能提升。
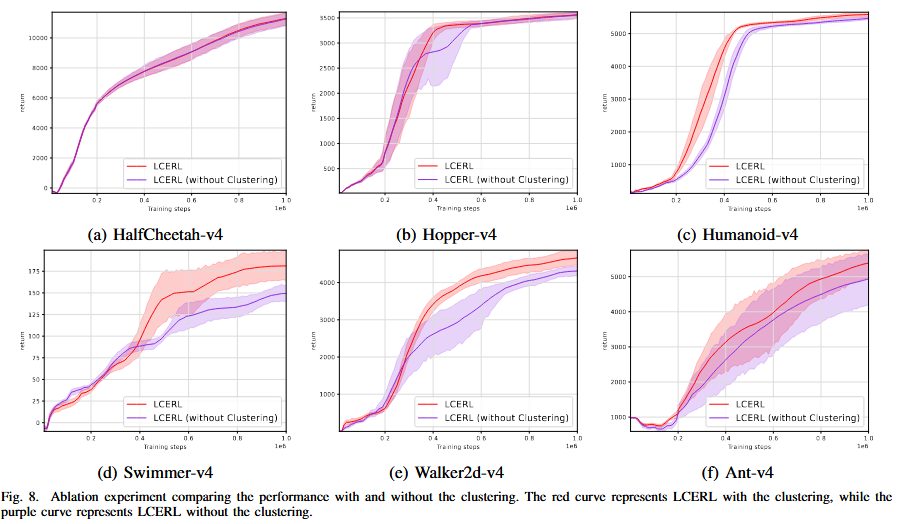
图 有无聚类选择机制的性能对比消融实验。
(3)真实能源调度任务验证
在真实能源调度(MEMG)任务中,我们进一步验证了LCERL在工程场景中的可落地性与实际价值。实验采用来自真实世界的热能、光伏与电力负荷数据,覆盖连续一年的运行周期,将其划分为231天训练集与125天测试集。在同等条件下,我们将LCERL与业内广泛使用的两类强化学习算法TD3与DDPG进行对比。结果表明,LCERL在训练阶段便展现出更快的收敛速度与更稳定的性能,标准差显著更小,说明其在能源管理任务中具备更强的鲁棒性。
更为关键的是,在真实测试集上的能源调度效果中,LCERL以显著优势实现了更低的累计能耗与更低的碳排放。根据实验统计,LCERL的成本与碳排放均为三者中最低,分别达到531.93千美元与7909.78吨,远低于TD3与DDPG。这意味着在实际调度中,LCERL能够以更优的策略完成能量分配任务,有效减少系统运行成本,并在碳减排方面展现出显著贡献。
这些结果证明,LCERL不仅在MuJoCo等模拟环境中表现突出,更能在真实复杂能源系统中稳定运行、显著降低能耗,充分体现其工程实用性与行业落地潜力,为未来智慧能源管理系统提供了坚实的技术支撑。
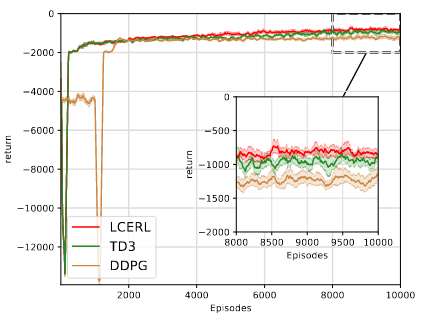
图 MEMG环境下的训练曲线。
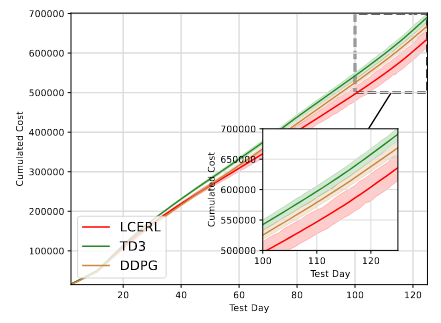
图 测试阶段MEMG环境下的实验结果。
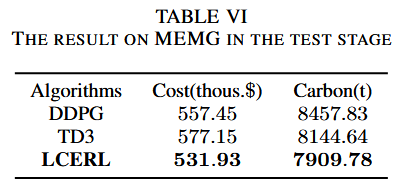
表 MEMG环境下的测试结果。
✨ 讨论与未来工作
本研究旨在解决进化算法对强化学习训练带来的负面影响,并进一步提升两者融合(ERL)的训练效率。为此,本研究提出了全新的LCERL算法,通过生成更高质量、更多样化的经验数据,显著增强了EA与RL之间的协同能力。算法中设计的三项核心机制——晚启动策略、双向对称近端变异以及基于归档的聚类选择——共同保证了高质量策略个体与经验的持续产生。实验结果显示,LCERL在收敛速度、稳定性与最终性能上均显著优于现有主流RL与ERL方法;同时,在真实能源调度场景中也展现出极强的工程可落地性。
尽管LCERL在多个任务中展现了领先表现,但仍存在进一步优化空间。例如,当前晚启动策略依赖固定超参数δ,未来将探索根据RL学习进度动态调整的自适应机制;双向对称近端变异虽然提升了策略质量,但其额外计算开销可能在资源受限环境下成为瓶颈,因此后续将考虑使用轻量化代理模型,并尝试将变异评估过程并行化,以充分释放现代GPU的算力。
此外,LCERL在真实世界能源调度任务(MEMG)中的成功应用,为其进一步推广到更复杂的现实系统奠定了基础。未来,团队将探索LCERL在机器人控制、智能电网调度以及动力电池管理等方向的潜在应用价值。面对这些领域中的不确定性、高维状态空间、延迟奖励与稀疏反馈等挑战,LCERL凭借其强大的探索-利用能力与对噪声和延迟的鲁棒性,有望成为解决复杂决策问题的有效途径。
✨ 原文链接(或点击阅读全文查看)
https://ieeexplore.ieee.org/document/11223076
CITATION:
Q. Cai, Y. -H. Jia, K. Zheng, S. Ou and W. -N. Chen, “Evolutionary Reinforcement Learning With Late-Start Evolution and Clustering Archive,” in IEEE Transactions on Evolutionary Computation, doi: 10.1109/TEVC.2025.3627631.
感谢您的关注,敬请期待更多团队动态!
初稿:连锦涛
排版:高伟敏
终审:贾亚晖,欧士琪